Die Robots.txt Datei – Der Guide 2019
In der Suchmaschinenoptimierung, aber auch bei Websites generell fällt immer wieder der Begriff ‚Robots.txt‘. Die meisten Websites haben eine robots.txt-Datei, aber das bedeutet nicht, dass die meisten Webmaster sie verstehen. In diesem Beitrag versuchen wir Ihnen die robots.txt Datei zu erklären und zu zeigen, wie sie den Zugriff auf Ihre Website kontrollieren und einschränken kann.
1. Was ist eine Robots.txt Datei?
Die robots.txt Datei teilt den Suchmaschinen die Regeln für das Engagement Ihrer Website mit.
Suchmaschinen überprüfen regelmäßig die robots.txt Datei einer Website, um zu sehen, ob es “directives”, also Anweisungen zum Durchsuchen der Website gibt.
Wenn keine robots.txt-Datei vorhanden ist oder wenn keine anwendbaren Richtlinien vorhanden sind, durchsuchen Suchmaschinen die gesamte Website.
Obwohl alle wichtigen Suchmaschinen die robots.txt Datei respektieren, können Suchmaschinen wählen, Teile der robots.txt, oder auch komplett zu ignorieren. Während Anweisungen in der robots.txt Datei ein starkes Signal für Suchmaschinen sind, ist es wichtig, sich daran zu erinnern, dass die robots.txt eine Reihe optionaler Anweisungen für Suchmaschinen und kein Mandat ist.
2. Wie funktioniert die Robots.txt?
Suchmaschinen durchforsten das Internet, um Inhalte zu entdecken. Diese Inhalte werden indexiert, sodass sie den suchenden Nutzern zur Verfügung gestellt werden können.
Um Websites zu durchsuchen, folgen Suchmaschinen Links, um von einer Website zur anderen zu gelangen. Dieses kriechende Verhalten wird manchmal als „Spinnen“ von der Spinne (engl. Spider) bezeichnet.
Nachdem er auf einer Website angekommen ist, aber bevor er sie mit einem Spider versehen hat, sucht der Crawler nach einer robots.txt-Datei. Wenn er eine findet, liest der Crawler diese Datei zuerst, bevor er mit der Seite weitermacht. Da die Datei robots.txt Informationen darüber enthält, wie die Suchmaschine crawlen soll, werden die dort gefundenen Informationen weitere Crawler-Aktionen auf dieser speziellen Website anweisen. Wenn die robots.txt keine Anweisungen enthält, die die Aktivität eines Benutzeragenten verbieten (oder wenn die Website keine Datei robots.txt hat), wird der Crawler auch andere Informationen auf der Website durchsuchen.
3. Beispiele einer Robots.txt
Im Folgenden finden Sie ein paar Beispiele für Inhalte von Robots.txt Dateien:
Beispiel-Domain: www.beispiel.de
URL der Robots.txt: www.beispiel.de/robots.txt
Klassisches Format einer Robots.txt:
User-agent: [user-agent name / Name der Suchmaschine, des Crawlers / * = Alle Crawler]
Disallow: [URL, Unterverzeichnis, Element, das vom Cralwen ausgeschlossen werden soll]
Blockieren aller Inhalte für alle Crawler:
User-agent: *
Disallow: /
Die Verwendung dieser Syntax in einer robots.txt-Datei würde allen Web-Crawlern sagen, keine Seiten auf www.beispiel.de zu crawlen, einschließlich der Homepage.
Erlauben aller Inhalte für alle Crawler:
User-agent: *
Disallow:
Die Verwendung dieser Syntax in einer robots.txt-Datei weist Web-Crawler an, alle Seiten auf www.beispiel.de zu durchsuchen, einschließlich der Homepage.
Blockieren eines gesamten Unterordners für einen bestimmten Crawler:
User-agent: Googlebot
Disallow: /beispiel-ordner/
Diese Syntax besagt, dass nur der Crawler von Google (Name des Benutzeragenten Googlebot) keine Seiten crawlen darf, die die URL-Zeichenkette www.domain.de/beispiel-ordner/ enthalten.
Blockieren einer bestimmten Unterseite für einen bestimmten Crawler:
User-agent: Bingbot
Disallow: /beispiel-ordner/blockierte-seite.html
Diese Syntax sagt nur dem Crawler von Bing (Name des Benutzeragenten Bing), um zu vermeiden, dass die spezifische Seite unter www.domain.de/beispiel-ordner/blockierte-seite.html durchsucht wird.
Blockieren von bestimmten URLs über Zeichen:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
Im obigen Beispiel wird * auf den entsprechenden Dateinamen oder Element erweitert, um diese auszusperren. Hier wird also alles mit ‘.php’ und alle ‘.jpg’ Bilder im Ordner ‘copyrighted-images’ blockiert.
4. Wo liegt die Robots.txt Datei?
Die robots.txt sollte immer im Stammverzeichnis Ihrer Domain/Website liegen. Wenn Ihre Domain also www.beispiel.de ist, sollten Sie die Robots.txt datei unter https://www.beispiel.de/robots.txt. finden.
Es ist auch sehr wichtig, dass Ihre Datei robots.txt tatsächlich robots.txt heißt. Der korrekte Name ist ausschlaggebend dafür, dass die Datei funktioniert.
5. Brauche ich eine Robots.txt?
Die Datei robots.txt spielt aus Sicht der Suchmaschinenoptimierung (SEO) eine nicht unwichtige Rolle. Sie sagt Suchmaschinen, wie sie Ihre Website am besten durchsuchen können.
Mit der robots.txt können Sie verhindern, dass Suchmaschinen auf bestimmte Teile Ihrer Website zugreifen, doppelte Inhalte verhindern und Suchmaschinen hilfreiche Tipps geben, wie sie Ihre Website effizienter durchsuchen können.
Seien Sie jedoch vorsichtig, wenn Sie Änderungen an Ihrer robots.txt vornehmen: Diese Datei hat das Potenzial, große Teile Ihrer Website für Suchmaschinen unzugänglich zu machen.
6. XML-Sitemaps in der Robots.txt
Obwohl die robots.txt Datei erfunden wurde, um Suchmaschinen mitzuteilen, welche Seiten nicht gecrawlt werden sollen, kann die Datei robots.txt auch verwendet werden, um Suchmaschinen auf die XML-Sitemap zu verweisen. Dies wird von Google, Bing, Yahoo und Ask unterstützt.
Die XML-Sitemap sollte als absolute URL referenziert werden. Die URL muss sich nicht auf demselben Host wie die robots.txt befinden. Das Verweisen auf die XML-Sitemap in der robots.txt Datei ist eine der besten Praktiken, die wir Ihnen immer empfehlen, auch wenn Sie Ihre XML-Sitemap bereits in der Google Search Console oder den Bing Webmaster-Tools eingereicht haben. Denken Sie daran, es gibt mehr Suchmaschinen da draußen.
Bitte beachten Sie, dass es möglich ist, mehrere XML-Sitemaps in einer robots.txt-Datei zu referenzieren.
Beispiel:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://www.beispiel.de/sitemap1.xml
Sitemap: https://www.beispiel.de/sitemap2.xml
7. Teste deine Robots.txt
In der alten Google Search Console gibt es noch immer die Möglichkeit, die Funktionalität und Richtigkeit seiner Robots.txt Datei zu testen:
https://www.google.com/webmasters/tools/robots-testing-tool
Wählen Sie einfach die entsprechende Property aus und geben Sie in das Textfeld unten die URL-Endung ein, auf die die Funktion der Robots.txt geprüft werden soll.
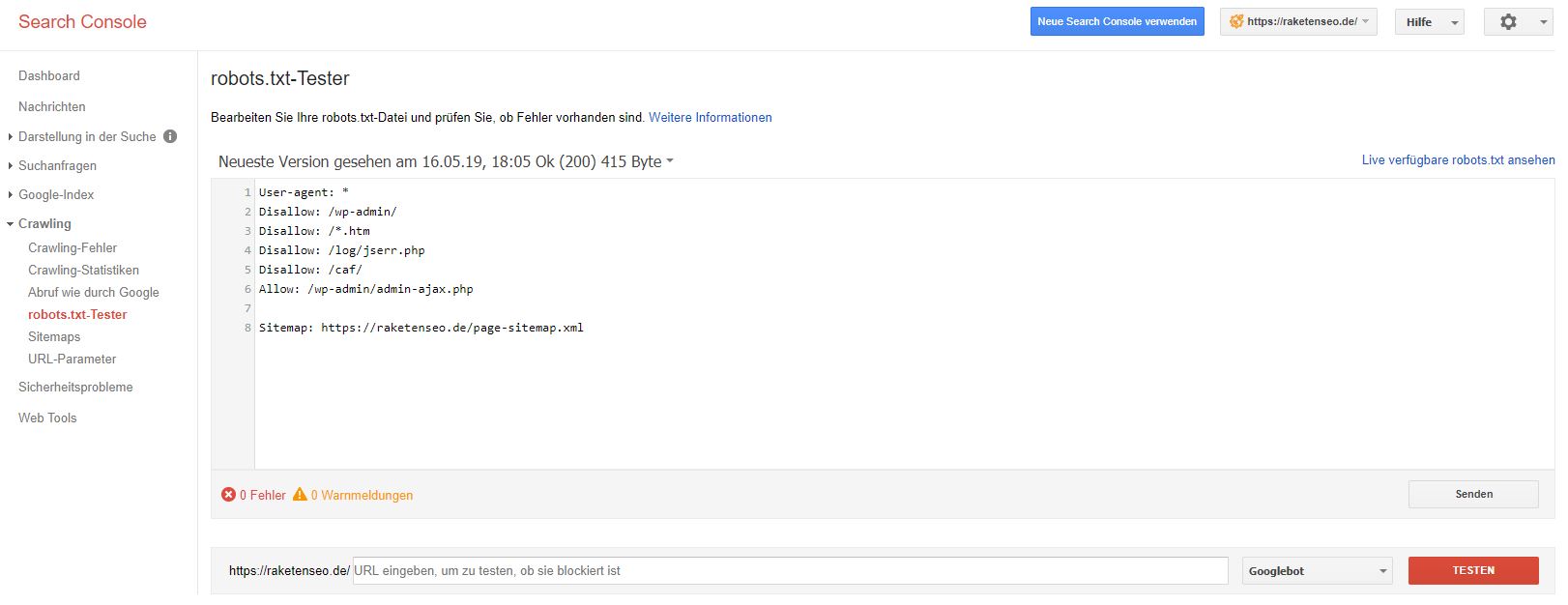
Wenn der jeweilige Crawler die URL lesen kann, erscheint rechts neben der Leiste in grün ‘Zugelassen’. Kann die URL ovm Crawler nicht gelesen werden, erscheint dort ein rotes ‘Blockiert’ und im Fenster darüber wird die Zeile mit dem Befehl aus der Robots.txt markiert, der diese URL blockiert.
{kind=link}
{kind=link}
Neueste Kommentare